
استفاده از نرمافزار پستولید برای قراردادن واقعگرایانهی اشیاء در صحنهها، برای کامپیوترها بهمراتب دشوارتر از انسانها است. انجام این کار نهتنها نیازمند تعیین مکانی مناسب برای شیء مدنظر است؛ بلکه به تلاش برای پیشبینی ظاهر شیء در محل هدف شامل مقیاس، انسدادها، حالت، شکل و… نیز احتیاج دارد.
خوشبختانه هوش مصنوعی وعدهی کمک در انجام این کار را میدهد. در مقالهای بهنام ترکیب و جای گذاری آگاه به متن نمونههای شیء که هفتهی گذشته در کنفرانس NeurIPS 2018 پذیرفته شد، پژوهشگران در دانشگاه ملی سئول و دانشگاه کالیفرنیا در مرسد و هوش مصنوعیگوگل سیستمی را توصیف میکنند که قراردادن شیء را درون یک تصویر بهنحو «معنادار و هماهنگ» یا بهعبارتدیگر، قانعکننده آموزش میبیند.
پروهشگران در مقالهی خود مینویسند:
قراردادن اشیاء درون تصویر که بهنحو معناداری با صحنه مطابق باشند، کار هیجانانگیز و جالبتوجهای است. این کار با بسیاری از کاربردهای دنیای واقعی، ازجمله ترکیب تصویر و ویرایش محتوای واقعیت افزوده و مجازی و تصادفیسازی دامنه بهشدت مرتبط است. چنین مدل قرارگیری اشیایی بهصورت بالقوه میتواند کاربردهای بیشماری از ویرایش تصویر و تجزیهوتحلیل صحنه را تسهیل کند.
چهارچوب دوطرفهی پژوهشگران دربردارندهی دو ماژول است: یکی محل قرارگیری شیء و دیگری ظاهری را تعیین میکند که آن شیء باید داشته باشد. این دو ماژول از شبکههای خصمانهی مولد (GANs) یا شبکههای دوبخشی عصبی بهره میگیرند که شامل مولدهای ایجادکنندهی نمونهها و تفکیکدهندههایی هستند که برای تمایز بین نمونههای ایجادشده و نمونههای دنیای واقعی تلاش میکنند. ازآنجاکه سیستم بهطور همزمان توزیع را باتوجهبه تصویر قراردادهشده مدلسازی میکند، به هر دو ماژول امکان میدهد با یکدیگر ارتباط برقرار و همدیگر را بهینهسازی کنند.
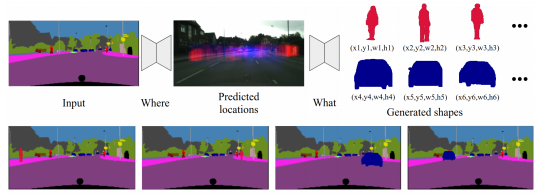
مؤلفان مقالهی مذکور مینویسند:
مهمترین ویژگی تازه و فنی این کار، ساخت شبکهی عصبی آموزشپذیر و دوطرفهای است که بتواند از توزیع مشترک خود، مکانها و اشکال مناسب را برای شیء جدید نمونهبرداری کند. نمونههای ترکیبیافتهی شیء برای ایجاد تصاویر جدید میتوانند بهعنوان ورودی برای روشهای مبتنی بر شبکهی خصمانهی مولد یا برای بازیابی نزدیکترین بخش از مجموعه دادهی موجود استفاده شوند.
آنطورکه پژوهشگران توضیح میدهند، مولد در این حالت مکان مناسب را برای ایجاد پوششهای شیء با مقیاسها و حالتها و شکلهای «معنادار و هماهنگ»، بهویژه چگونگی توزیع اشیاء در صحنه و نحوهی قراردادن طبیعی شیء پیشبینی میکند تا اشیاء بهعنوان بخشی از صحنه بهنظر برسند. سیستم Artificial Intelligence بهتدریج در مسیر آموزش، توزیع مختلفی را برای هر دستهبندی شیء یاد میگیرد که در صحنه قرار دارد. برای مثال، هوش مصنوعی این حقیقت را میفهمد که در تصاویری از خیابانهای شهر، مردم معمولا در پیادهروها و خودروها اغلب در جادهها حضور دارند.
در آزمایشها، مدل پژوهشگران با ورود واقعگرایانهی اشیای شکلیافته عملکردی بهتری درمقایسهبا حالت اولیه از خود نشان داد. وقتی تشخیصدهندهی تصویر (YOLOv3) روی تصاویر ساختهشدهی هوش مصنوعی اجرا شد، میتوانست اشیای ترکیبشده را شناسایی کند. در برآورد کارکنان سرویس ترک مکانیکی آمازون، بهنحو مؤثرتر ۴۳درصد از شرکتکنندگان به این باور رسیدند که اشیای ساختهشدهی هوش مصنوعی واقعی هستند.








